Technology and Cloud Services
Our Strengths
Multi-Disciplinary Teams
Blended expertise in science (Biology, Chemistry) and technology (AI/ML, Data, and Cloud) helps us to seamlessly collaborate with our client’s biopharma R&D teams and build enterprise-class vertically integrated in silico solutions
Resuable Building Blocks
State-of-the-art Techniques
We leverage open-source tools and build proprietary applications, platforms, and technologies to expand the application of in silico techniques to emerging therapies and modalities
Key Considerations
Building high throughput computational biology and chemistry solutions depend on a number of factors
Science Focus
Application Centricity
Pipelining
Algorithms & Data Structures
Infrastructure Scaling
Customizable and Configurable
Technology and Cloud - Solution Areas and Building Blocks
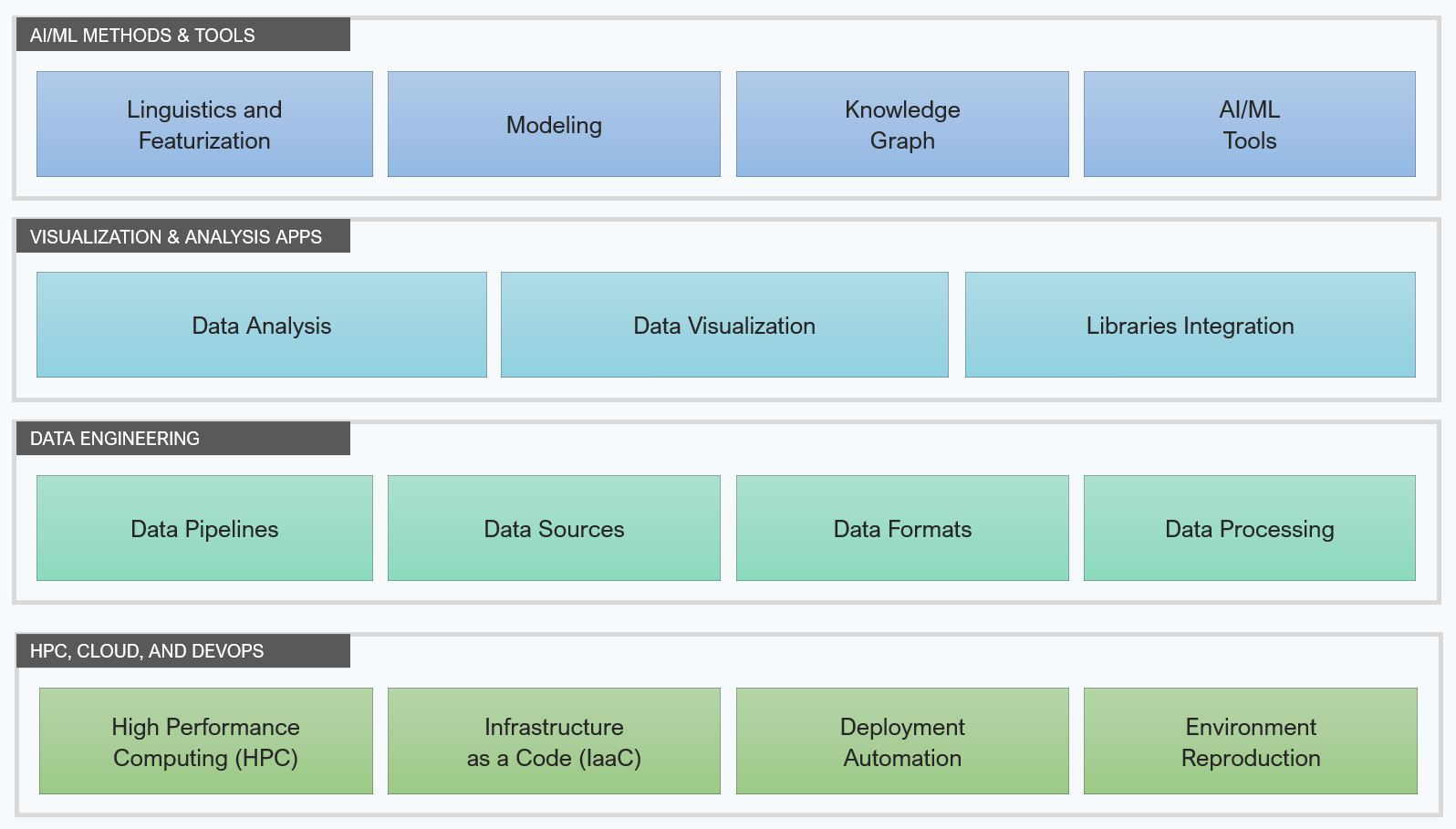
Solution areas
Solution area
HPC , Cloud and DevOps
We build cloud and automation solutions to easily configure, customize, and scale on-demand computing resources, reducing manual effort in executing and managing computational biology and chemistry processes.
High-Performance Computing (HPC)
- Stand up high-performance clusters to analyze complex and large-scale multi-omics (Genomics, Transcriptomics, Proteomics) and quantum chemistry computational workloads rapidly and efficiently across on-premises, cloud, or hybrid environments
Infrastructure-as-a-code (IaaC)
- Define and customize infrastructure specifications consistently, on-demand, and quicker with IaaC strategy and automation leveraging design frameworks and industry-leading tools such as AWS, CloudFormation, Terraform etc.
Deployment Automation
- Package and deploy several computation workloads into containerized application clusters leveraging tools (e.g., Kubernetes/SLURM-like schedulers) that help to automate deployment, parallelize execution of workloads at scale, and auto-scale on-demand resulting in faster development, testing, and production rollouts
Environment Reproduction
- Ensure provision of unified development platforms and easily reproducible run-time environments leveraging tools such as Spark, Docker, and Singularity that help multiple teams of engineers, scientists, and analysts to collaborate efficiently in executing machine learning and real-time workloads
Solution area
Data Pipelines
We design scalable data engineering pipelines that cater to various data sources, formats, integration, and high throughput processing needs while leveraging existing clients' proprietary public data for developing computational biology and chemistry solutions.
Data Pipelines
- Design and build robust, high-performance, and end-to-end Omics, NGS, and quantum chemistry data engineering pipelines with tools such as Cromwell (from Broad Institute), Apache Airflow, Luigi, AWS Glue, etc., that help to programmatically author, schedule, orchestrate, and monitor scientific workflows and data lineage
Data Sources
- Integrate with large biology and chemistry data sources such as Biobanks, GenBank, Cell Atlases, Clinical trial repositories, PubChem, PubMed, PDB, Variant effect databases, etc., making it easier for biopharma R&D teams to execute drug discovery and development processes leveraging public data sets integrated with proprietary data sets
Data Formats
- Process data and perform complex calculations at high speeds of several bioinformatics and biochemistry data sets – nucleotide sequences, amino acid sequences, large-scale genotyping and DNA sequencing etc., represented in popular data formats such as FASTA/FASTQ, SAM/BAM, VCF, etc.
Data Processing
- Distribute and process-in-parallel large-scale data sets related to biopharma processes such as genome analysis, NGS, molecular modeling etc., across multiple computing resources leveraging tools such as Apache Spark/Dask helping to maximize usage of computing resources and reduce processing time
Solution area
Visualization and Analysis App
We build custom applications and integrate/extend widely used platforms that help biopharma R&D teams easily explore, analyze, and visualize complex computational biology and chemistry data and relationships.
Data Analysis & Visualization
- Create, visualize, and share biological and chemical computational analyses leveraging Jupyter/RStudio based notebook development that helps data scientists to integrate live code, equations, computational output, visualizations, and other multimedia resources, along with explanatory text in a single document accelerating downstream analysis of BioChem assays
Custom Data Visualization
- Design and develop additional interactive web-based applications for dynamic and interactive data analysis and visualization leveraging modern UI frameworks such as ReactJS and D3.js helping biopharma R&D teams to easily explore, manage, and visualize scientific data and charts
Library Integration
- Develop APIs and integrate Jupyter/RStudio notebooks and web applications with popular libraries and tools such as Hail, scVerse/Seurat, Maxquant/Perseus etc., that help in seamlessly analysing and exploring omics data sets, single-cell RNA-seq data, large mass-spectrometric data sets etc.
Solution area
AI/ML methods & tools
We leverage advanced AI and ML algorithms, tools, and techniques for the predictive modeling of complex molecular structures, sequences, and interactions thereby, accelerating drug discovery and development.
Linguistics and Featurization
- Deep learning based featurization of Bio and Chemical entities. E.g., Protein embeddings, Graph Convolution, and Circular fingerprints based molecular featurization.
- mRNA and Antibody Design leveraging search/filter algorithms from computational linguistics to optimize folding stability and translation efficiency for arriving at an optimized mRNA sequence structure
Modeling
- Modeling of structure from sequence, prediction of protein interactions, and identification of likely binding sites. Time-series modeling with deep learning for biosynthesis processes such as mAb synthesis, QSAR, QSPR Modelling to make accurate biological activity and ADMET predictions spanning a diverse chemical space
Knowledge Graph
- BioChem entity extraction and annotation with low-code configuration and declarations driven solutions leveraging NLP alongside vocabularies and ontologies such as UMLS and GO. Knowledge graph construction from public and private research and clinical data into graph databases such as Neo4J
AI/ML tools
- Leveraging AI/ML Tools such as TensorFlow, PyTorch on GPUs, MLOps with WandB etc., to develop, train, and manage AI/ML models and associated workflows across the lifecycle