Computational Biology Services
Developing in silico solutions in the areas of drug discovery, precision medicine and treatment of genetic disorders
We develop and deploy in silico solutions that complement the traditional lab-based approaches to accelerate drug discovery and development for biopharma R&D. We build multi-omics (Genomics, Transcriptomics, and Proteomics) solutions for our clients by blending the concepts of bioinformatics and computational biology with advances in AI/ML, Cloud, Data, and DevOps.
Our Strengths
Multi-Disciplinary Teams
Blended expertise in science (Biology, Chemistry) and technology (AI/ML, Data, and Cloud) helps us to seamlessly collaborate with our client’s biopharma R&D teams and build enterprise-class vertically integrated in silico solutions
Building Blocks
Reusable and easily integrable in silico components for next-generation sequencing, multi-omics pipelines, knowledge graph creation, and computational infrastructure provisioning, accelerating solutions development
Customizable Solutions
Computational Biology - Solution Areas and Building Blocks
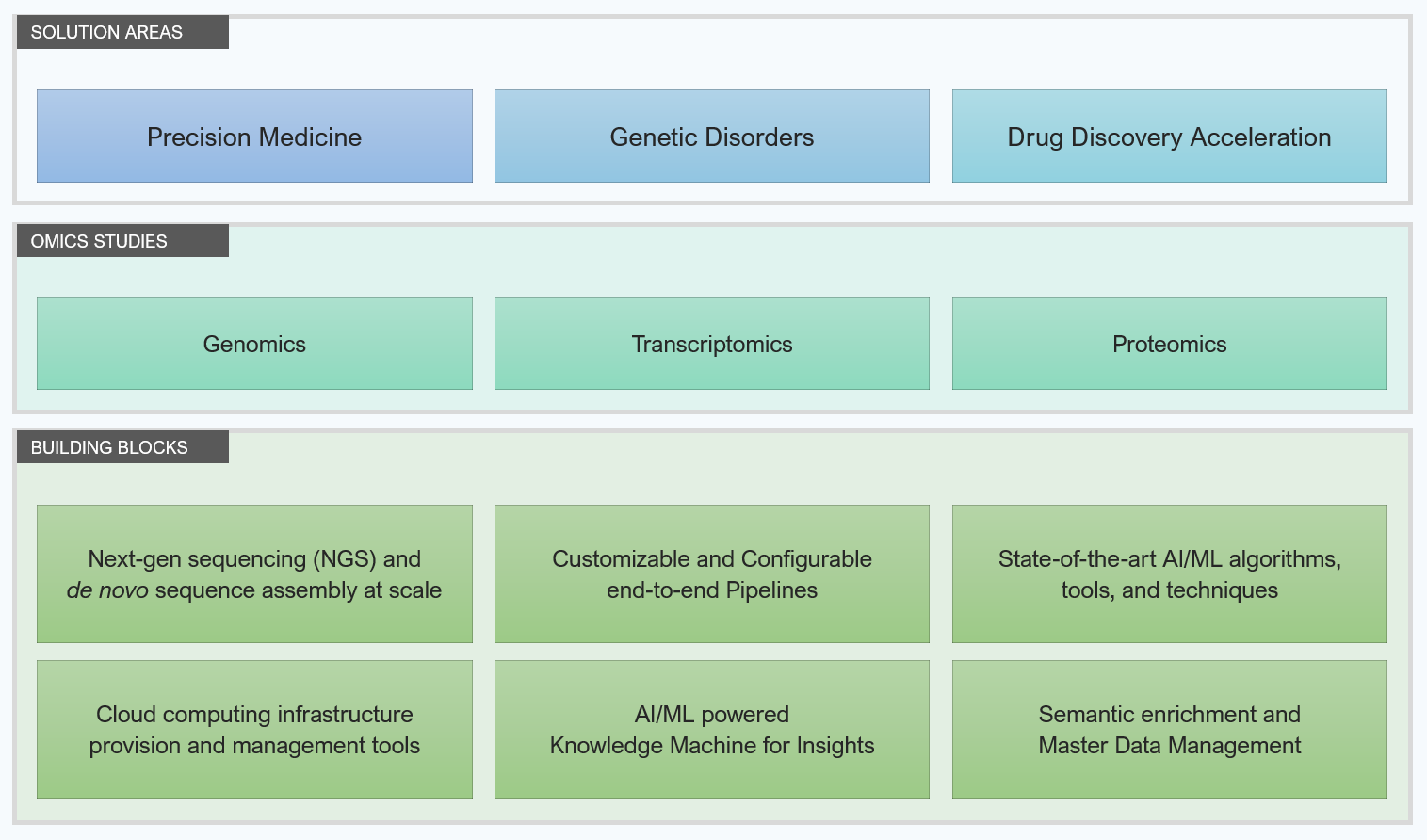
Solution areas
Solution area
Drug Discovery
As researchers repeatedly iterate in developing optimal drug lead candidates, computational methods advance the field by narrowing potential candidates, providing faster results, and augmenting the wet lab processes. We develop in silico solutions to efficiently navigate ever evolving complex multi-dimensional data and interconnections, at scale, thereby accelerating drug discovery and development
Genomics
- A variety of high-throughput next-generation sequencing technologies to transform the analysis of B cells and their antibody repertoires
Transcriptomics
- In silico platform to design complete end-to-end sequences of mRNA therapeutic candidates
- Single-cell transcriptomics to separate cells into functionally different populations and understand cell functions based on the transcribed genes read more…
Proteomics
- In silico models such as antibody structure prediction and antigen docking, to complement and accelerate in vitro/in vivo experiments.
- Mass spec based pipelines for quantitative profiling of biomolecules such as antibodies read more…
Solution area
Genetic Disorders
Therapeutic advances like gene therapy and antisense oligonucleotide (ASO) therapy help correct genetic disorders. We build gene therapy pipelines for the identification of efficient viral vectors, investigation of safety profiles, prediction of off-targets, and recognition of targets for Antisense oligonucleotides (ASO)
Genomics
- An automated pipeline to identify and harvest naturally occurring viral vectors from fused genomes and produce more efficient, broad tropism viral vectors.
- Optimized Vseq toolkit for the analysis of viral vector fusion events
- GWAS pipelines to associate variants to a disease
Transcriptomics
- Differential gene expression to understand alternative splicing patterns, therefore, better target identification.
- Prediction of splice junctions from transcriptomics data to estimate inclusion/exclusion of an exon
Solution area
Precision Medicine
Precision medicine uses information about a person’s genome/proteome to diagnose diseases or adjust medications exclusively for that person. We build custom high-throughput multi-omics analysis solutions to gain insights into genotype to phenotype associations, understand elusive molecular mechanisms, and develop innovative precision treatment options.
Genomics
- Clinical genomics studies to enable better/informed stratification of patients into groups and sub-groups.
- Genome analysis to identify genetic variants that may identify responders from non-responders.
Transcriptomics
- Gene expression studies to identify therapeutic targets and gene expression signatures, helping to predict response to therapies, such as cancer
Proteomics
- Biomarker-driven approach to predict the likelihood of therapeutic response.
- Quantitative measurements enable characterizing a protein’s biological proces read more…
Building Blocks
We have built building blocks to accelerate the development of new computational biology solutions
Next-gen sequencing (NGS) and de novo sequence assembly at scale
Sampling and data analysis tools for different sequencing methods such as RNA-Seq, DNA-Seq, ChIP-Seq, Small RNA-Seq, Genome Browser, Visualizations etc, capable of handling large volumes of public and private data sets. Tools to assemble individual sequences without reference sequence (de novo Genome Assembly)
Customizable and configurable end-to-end Omics Pipelines
End-to-end enterprise-class, cloud-hosted, and customizable pipelines for conducting multi-omics analysis and genome-wide association studies (GWAS) built on Hail and Cromwell platforms and integrated with Illumina BaseSpace, PacBio SMRT Link, 10x Genomics Cell Ranger, Trans-Proteomic Pipeline
State-of-the-art-technologies
Development of machine learning and deep learning models for prediction, classification, and feature selection related to several computational biology solutions. Examples – Deep Neural Networks (DNN) for phenotype analysis, Homology modeling and deep learning (RosettaSuite, Deep H3, Alphafold2) for antibody structure prediction, SpliceAI/MMsplice for splice site prediction
Configurable, scalable, and on-demand cloud computing infrastructure
Cloud computing infrastructure provision and management tools: Infrastructure-as-a-code driven solutions for providing on-demand and auto-scalable computational resources with minimal technical effort. Compatible with any cloud provider supporting Kubernetes, including major vendors such as AWS, GCP, and Azure. Compatible with classic HPC schedulers such as SLURM and SGE for workload management
Insights generation
Integrated knowledge graph creation tools by continuously crawling, mining, identifying, resolving, and linking biopharma entities from research and clinical data found in published research and other relevant public and private content artifacts. Master data services to disambiguate, resolve and integrate: interventions, indications, studies, and organizations
Faster discovery of entities and relationships through semantic enrichment
A low-code configuration and declarations-driven tool for extracting and resolving entities and associating them based on ontologies and vocabulary databases. Further classifying, ranking, and summarizing entities with advanced NLP and AI techniques. This tool is designed to be easily integrated with any of the bioinformatics pipelines as a data enrichment component