Large Language Models for Chart Review Automation in Medical Affairs

The Evolution of Chart Reviews: From NLP to LLMs
Traditionally, chart reviews have been labor-intensive, requiring meticulous manual extraction of relevant information from patient records. This not only consumes valuable time but also introduces potential human error. First attempts at automating chart reviews were enabled by Natural Language Processing (NLP) techniques such as named entity extraction, relationship extraction, and negation detection. While these enabled automation, resulting automation was limited and fragile as these techniques relied on previous generation ML technologies.
Enter Large Language Models (LLMs). These advanced AI systems are revolutionizing chart reviews, not only enabling faster and more accurate extraction of relevant clinical information but also expanding the type and scope of information that can be extracted.
In this blog, we will explore how automated chart reviews are evolving from fragile Natural Language Processing (NLP) systems, to sophisticated LLMs.(Figure 1)

Real-World Application: A Study on HCC Imaging Reports
To illustrate the impact of LLMs, consider a recent study, Ge et al., 2024 on hepatocellular carcinoma (HCC) imaging reports. The study evaluated the efficacy of an LLM, specifically Versa GPT-4 implemented via a PHI-compliant Microsoft Azure OpenAI API, in extracting data elements from HCC imaging reports. The LLM’s performance was compared to traditional manual chart reviews, focusing on the extraction of eight specific data elements.
The study addressed the following questions:
- Can the LLM extract information from medical notes and convert it into various data formats?
- How does the LLM’s performance in extracting eight specific data elements from HCC imaging reports compare to manual chart reviews in terms of accuracy, precision, recall, specificity, and F1 scores?
- Is the LLM capable of extracting information accurately when given complex instructions?
Performance of LLM in the study
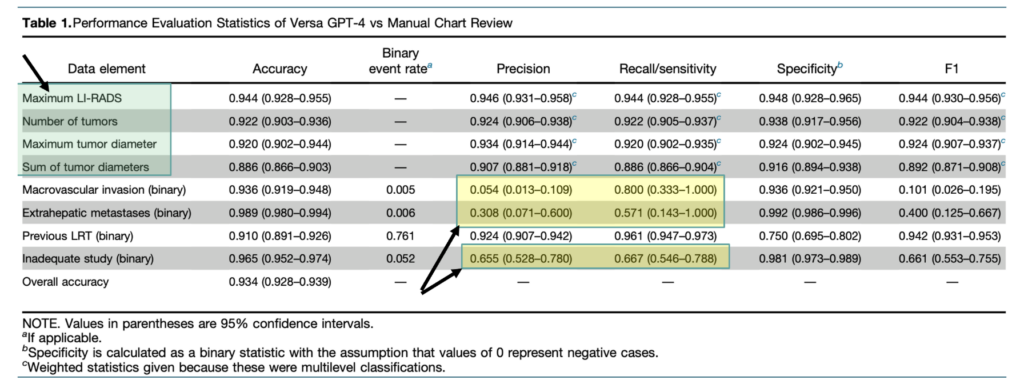
Figure 2 shows the performance of LLM on extraction of each of the data elements requested in the prompt shown in figure above.
The LLM performs better (high accuracy and high precision) on the first four data elements— LI-RADS scores, number of tumors, tumor diameter and tumor diameters—because these tasks involve extracting structured, numerical, or categorical data that is consistently presented in imaging reports. These elements have clearer contextual cues, allowing for high accuracy and precision.
In contrast, the high accuracy but low precision for 3 of the 4 binary classification tasks, such as detecting macrovascular invasion or extrahepatic metastases require more nuanced interpretation of variable and often implicit language in the reports. The complexity of these decisions, coupled with potential data imbalance and the need for clinical judgment, results in lower precision, recall, and overall performance for these elements.
Enhancing LLM Performance with Aganitha’s ARCTM Patterns
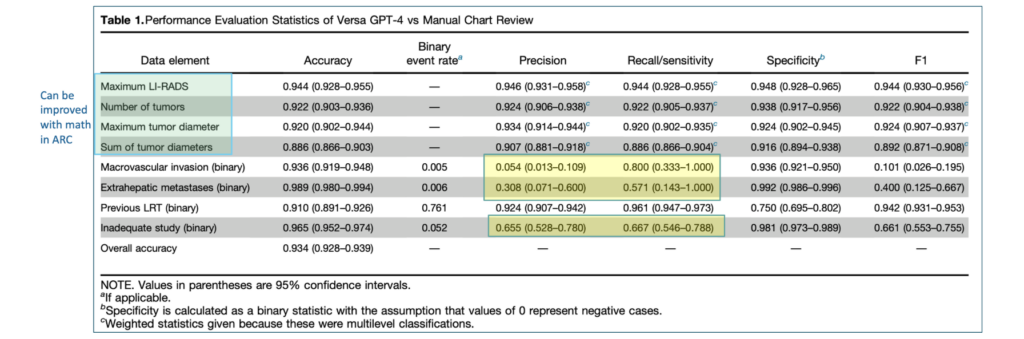
While LLMs have significantly advanced the field of chart reviews, there are areas where their performance can be further optimized. For example, while the accuracy, precision and recall of the first four elements listed in the table below are in high 90s, they can be further improved to near 100% by recognizing that all of these elements are numeric and require ability to count, compare and add – skills LLMs are not very good at by default, but can excel with the help of a math plugin. Similarly, the precision and recall of 3 out 4 binary elements need to be significantly improved. This is where Aganitha’s AI as Research Collaborator (ARC™) framework helps.(Figure 3)
ARC™ enhances the performance of LLMs in the context of biopharma research, clinical, medical and regulatory affairs by enabling LLMs to make use of additional tools, reference data sources and solution patterns.
Conclusion
Large Language Models are powerful tools in the medical field, transforming how clinical trials are conducted. By automating the extraction of complex data from medical charts, LLMs have the potential to not only improve patient care but also accelerate medical research and development.
Aganitha ARC™ allows you to further build on the capabilities of LLM in the context of specific requirements in medical affairs and broader biopharma R&D, clinical and regulatory affairs.
To learn more about LLMs and ARC™, click here or contact us today!